Imputation
for Nonresponse in Surveys
PUBHBIO 7225 Lecture 19
Imputed Items Tend to Have Low Nonresponse Rates
Demographic variables are the most commonly imputed (for use in weight adjustments)
Item nonresponse for these items tends to be low
Example: National Survey of Children’s Health (NSCH) – 2022
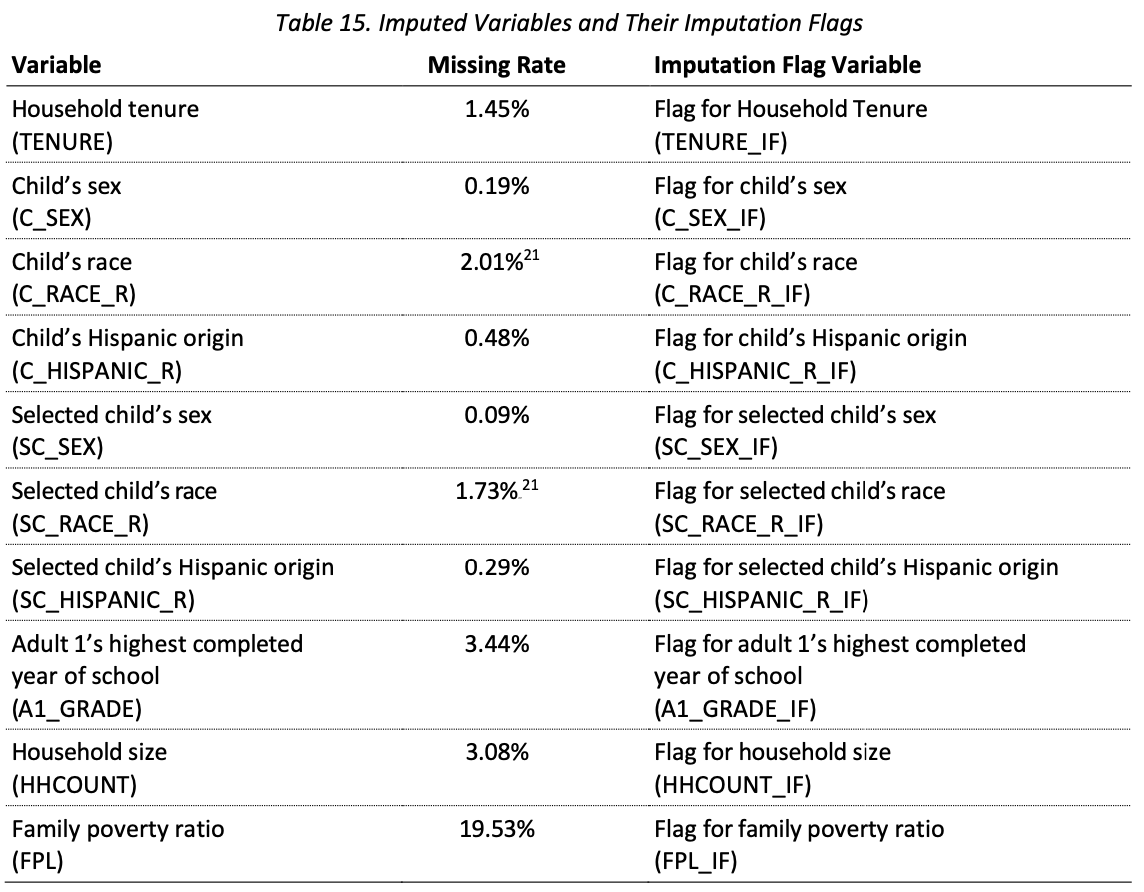
Screener sample size = 127,726
- Most missingness: Child’s race – 2,568 missing (2.01%)
Topical survey sample size = 54,103
Most missingness: Poverty ratio – 10,567 missing (19.53%)
Next most missingness: Adult education – 1,860 missing (3.44%)
Very low rates of missingness for all demographics except poverty level
Poverty level based on income – usually high nonresponse for income on all surveys!
Source: 2022 NSCH Methodology Report, p.40
Hot Deck Imputation
Hot Deck Imputation = Replacing missing values of one or more variables for a nonrespondent (“recipient”) with observed values from a respondent (“donor”) that is similar with respect to characteristics observed for both
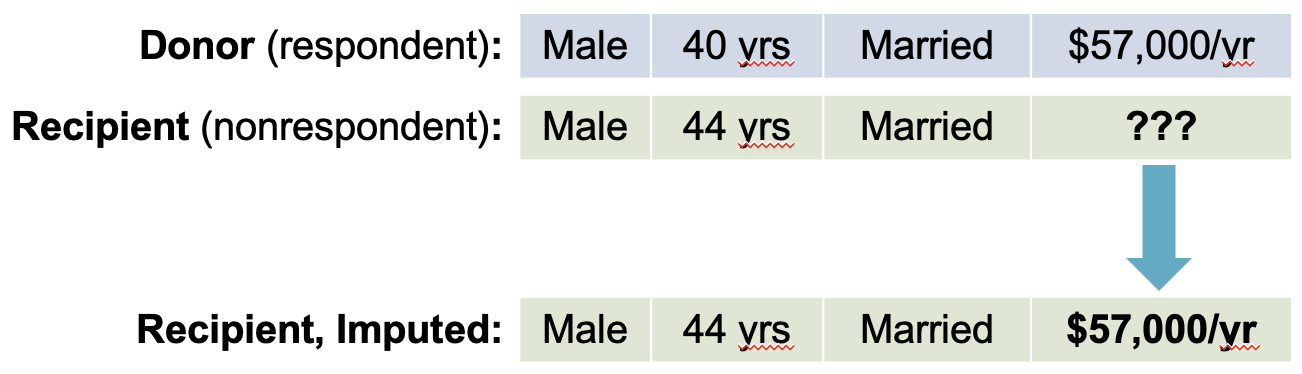
Why is it “Hot”?
Throwback to punch cards for computers
Donors come from cards currently being processed (“hot”)
Alternative: “Cold” deck = data from external data set
Sequential Regression Imputation
(the sometimes-used imputation method for surveys)
Sequential Regression Imputation = Replacing missing values of one or more variables for a nonrespondent with a draw from a predictive distribution that is based on a regression model
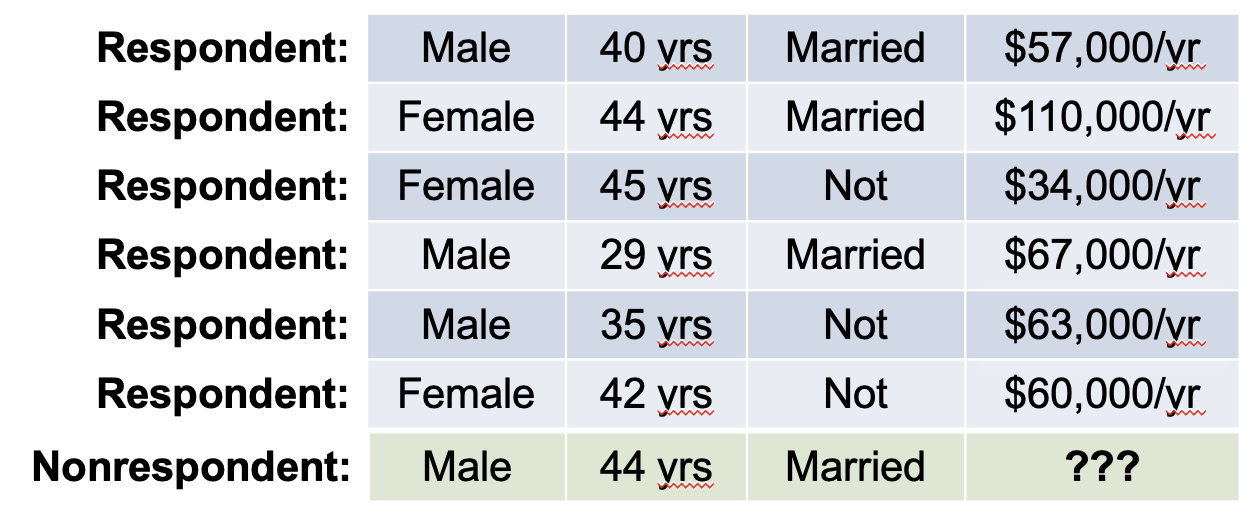
To impute missing income value:
Predict income using gender, age, and marital status as covariates in regression model
Obtain prediction for the nonrespondent’s income based on the model
Add extra “noise” to both the regression coefficients and the imputed value
This is a simplification of a complex process!
Imputation Is Complex!
Lots and lots of possible methods…
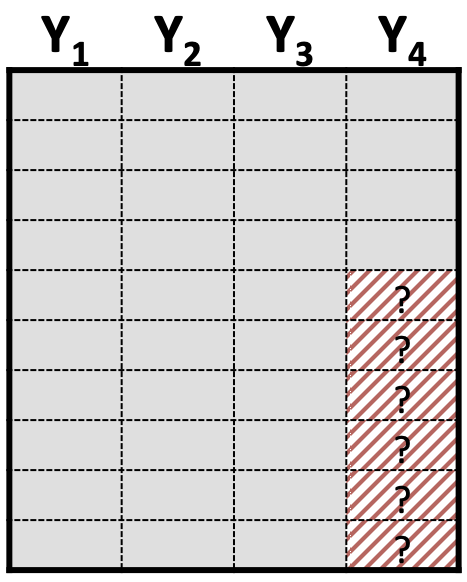
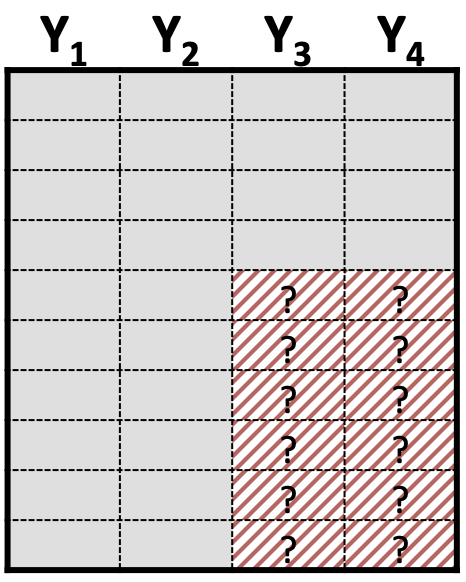
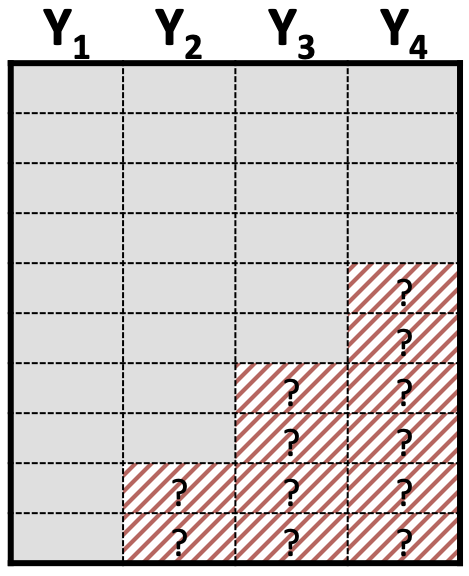
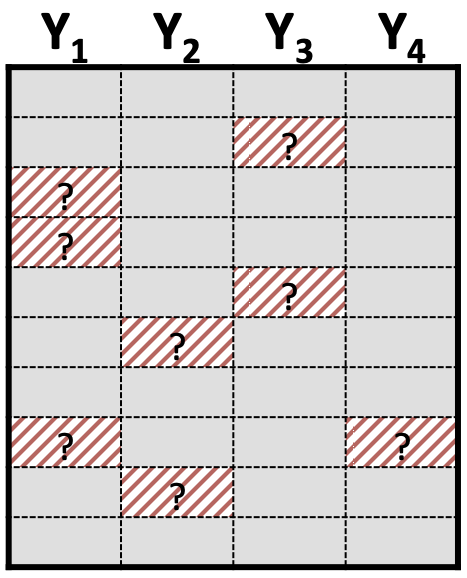
Added complexity of different patterns of missing data:
- Want to know more about missing data and imputation?
- We have a whole course: PUBHBIO 7240/STAT 6520 (Applied Statistical Analysis with Missing Data)